常见排序算法的总结
排序算法属于计算机知识体系中的基础知识,在各大程序语言中都会出现它的身影,底层的编译器本身也有对排序的优化实现。 本文对常见的排序算法做个梳理总结,理解并掌握这些排序算法有助于提升自身的编程水平,写出性能更高效的代码。
冒泡排序
冒泡排序是很多人在学习编程时,接触到的第一种排序算法,它比较简洁直观。经过每一轮的处理,最大的(或最小)那个数,会像水泡一样从底下冒上来。 经过多轮的处理,整个数字序列也就变得有序了。
我们拿一组简单的数字 [1, 9, 3, 8, 7, 5]来举例,进行数字的升序排序。冒泡排序每轮都会,进行前一个数和后一个数的比对,如果前者大于后者,则进行交换。 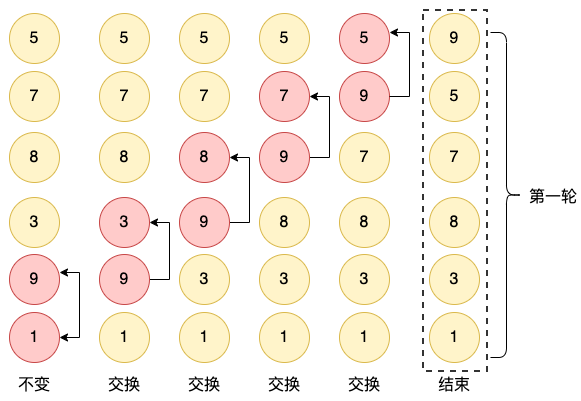
经过第一轮的比较,最大的数字 9 在两两比较的过程中,逐次被交换到了后面,也就“冒泡”升到了最上面的位置。 同理,经过第二轮的比较,数字 8也会被交换到倒数第二的位置。依次类推,则是7、5、3、1,最终形成了有序的集合:[1, 3, 5, 7, 8, 9]。
我们看一下代码实现:
/**
* @param {number[]} nums
* @returns {number[]}
*/
function bubbleSort(nums) {
const n = nums.length;
let isChanged;
for (let i = n - 1; i >= 0; i--) {
isChanged = false;
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
[nums[j], nums[j + 1]] = [nums[j + 1], nums[j]];
isChanged = true;
}
}
console.log('loop: ', nums.join(', '));
if (!isChanged) {
// 没有发生交换,说明剩余数字都是有序的,跳出循环即可
break;
}
}
return nums;
}/**
* @param {number[]} nums
* @returns {number[]}
*/
function bubbleSort(nums) {
const n = nums.length;
let isChanged;
for (let i = n - 1; i >= 0; i--) {
isChanged = false;
for (let j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
[nums[j], nums[j + 1]] = [nums[j + 1], nums[j]];
isChanged = true;
}
}
console.log('loop: ', nums.join(', '));
if (!isChanged) {
// 没有发生交换,说明剩余数字都是有序的,跳出循环即可
break;
}
}
return nums;
}这里我们输出每一轮的结果,验证一下。
- loop: 1, 3, 8, 7, 5, 9
- loop: 1, 3, 7, 5, 8, 9
- loop: 1, 3, 5, 7, 8, 9
- loop: 1, 3, 5, 7, 8, 9 (没有发生交换,结束循环)
- [ 1, 3, 5, 7, 8, 9 ]
可以看到,每轮loop过后,序列从后往前有序的集合在不断扩大。
冒泡排序要经过内外两层的for循环,不需要额外的存储空间,因此冒泡排序的时间复杂度是 O(n^2),空间复杂度是 O(1)。
插入排序
插入排序,也很好理解,就像我们玩扑克牌游戏的时候,会把摸到的扑克牌按照从小到大的顺序,插入到原有的集合中,形成方便观察的数字序列。
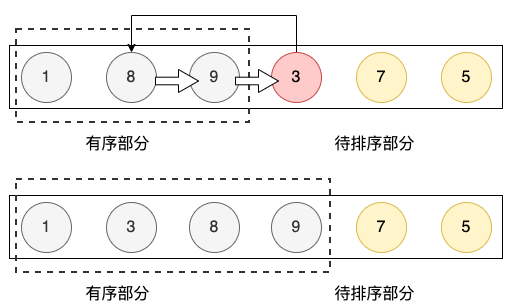
- 预先假定一个有序的子集(初始阶段就一个元素)
- 每当排入下一个元素时,依次从后向前 和 有序子集的元素对比
- 凡是小于有序子集中的元素值,就向后移动一个位置
- 当移动到比有序子集中的元素大时,停止移动,记录此时的索引index
- 将当前的待排序位置元素 和 索引index位置的元素交换
我们看一下代码实现:
/**
* insertion sort
* @param {Number[]} ary
*/
const insertSort = (ary) => {
const n = ary.length;
for (let i = 1; i < n; i++) {
let j = i;
const curr = ary[j];
while (j > 0 && curr < ary[j - 1]) {
const temp = ary[j];
ary[j] = ary[j - 1];
ary[j - 1] = temp;
j--;
}
console.log('loop: ', nums.join(', '));
ary[j] = curr;
}
return ary;
};/**
* insertion sort
* @param {Number[]} ary
*/
const insertSort = (ary) => {
const n = ary.length;
for (let i = 1; i < n; i++) {
let j = i;
const curr = ary[j];
while (j > 0 && curr < ary[j - 1]) {
const temp = ary[j];
ary[j] = ary[j - 1];
ary[j - 1] = temp;
j--;
}
console.log('loop: ', nums.join(', '));
ary[j] = curr;
}
return ary;
};输入 [1, 9, 3, 8, 7, 5],输出每一轮的结果如下:
- loop: 1, 9, 3, 8, 7, 5
- loop: 1, 3, 9, 8, 7, 5
- loop: 1, 3, 8, 9, 7, 5
- loop: 1, 3, 7, 8, 9, 5
- loop: 1, 3, 5, 7, 8, 9
- [ 1, 3, 5, 7, 8, 9 ]
可以看出,插入排序不同于冒泡排序,是前面先有序且有序集合在每轮过后长度加1。
同样插入排序也要经过内外两层的for循环,所以时间复杂度为O(n^2),不需要申请额外的内存空间,所以空间复杂度为O(1)。
选择排序
选择排序,是每轮从未排序的部分中抽出一个最小的,放置到当前待排序位置上。
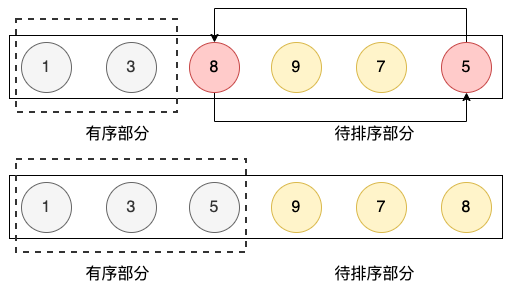
- 初始将当前待排的元素(8)设置为最小值minValue
- 依次从待排序的子集中,寻找小于 minValue 的元素结点
- 如果 找到了,重置该元素为 minValue
- 本轮过后,交换当前待排位置 和 最小位置的元素结点
看一下代码实现:
function selectSort(nums) {
const n = nums.length;
for (let i = 0; i < n; i++) {
let minIdx = i;
let minVal = nums[minIdx];
for (let j = i + 1; j < n; j++) {
if (nums[j] < minVal) {
minVal = nums[j];
minIdx = j;
}
}
if (minIdx !== i) {
[nums[i], nums[minIdx]] = [nums[minIdx], nums[i]];
}
console.log('loop: ', nums.join(', '));
}
return nums;
}function selectSort(nums) {
const n = nums.length;
for (let i = 0; i < n; i++) {
let minIdx = i;
let minVal = nums[minIdx];
for (let j = i + 1; j < n; j++) {
if (nums[j] < minVal) {
minVal = nums[j];
minIdx = j;
}
}
if (minIdx !== i) {
[nums[i], nums[minIdx]] = [nums[minIdx], nums[i]];
}
console.log('loop: ', nums.join(', '));
}
return nums;
}- loop: 1, 9, 3, 8, 7, 5
- loop: 1, 3, 9, 8, 7, 5
- loop: 1, 3, 5, 8, 7, 9
- loop: 1, 3, 5, 7, 8, 9
- loop: 1, 3, 5, 7, 8, 9
- loop: 1, 3, 5, 7, 8, 9
- [ 1, 3, 5, 7, 8, 9 ]
选择排序,在每轮中要找到最小的元素和当前位置的结点交换,它也是一种不稳定的排序方式。
所谓稳定性,就是所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,我们就说这种排序方法是稳定的。反之,就是非稳定的。
举个例子,序列ary = [5 7 5 3 10],第一遍循环中选择第 1 个元素 5 会和 3 交换,那么原序列中两个5的相对前后顺序就被破坏了,所以选择排序是一个不稳定的排序算法。
和冒泡、插入排序算法一样,选择排序的时间复杂度为O(n^2),其空间复杂度为O(1)
快速排序
快速排序,一种应用广泛,同时也是面试中常考的一种排序算法。它的核心要点是,选择一个元素作为参考,比它小的元素,移动到左边,比它大的元素移动到右边,最后再把左边部分的元素集合、参考元素、以及右边的元素集合组成在一起。
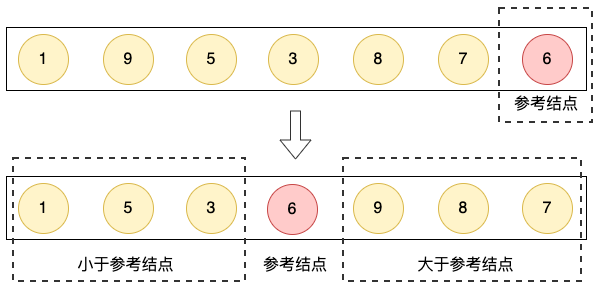
每轮都将集合切分成【左边,中间,右边】三部分,当切分的粒度小到1时,整个数据集合就变成有序的了。 快排在这里也体现了分治的思想,它和下面介绍的归并排序都用到了这一思想。
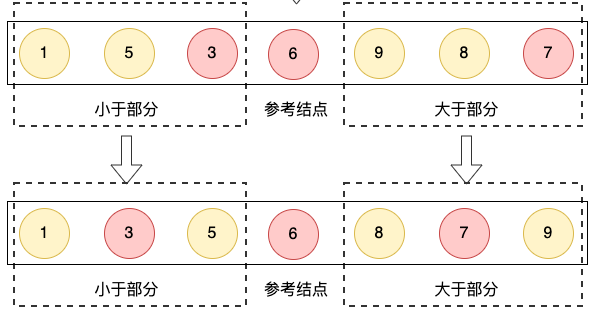
将整体切分成部分,每个部分都有序后,整体也就有序了。从上图我们可以直观看到,经过两轮的处理,左边的部分【1,3,5】已经有序了,而右边的【8,7,9】经过最多两轮就有序了。
我们看一下快速排序的代码实现:
function quickSort(ary) {
if (ary.length < 2) return ary;
// 确定参考结点的索引位置,取中间位置的结点
const centerIndex = ary.length >> 1;
// 参考结点
const pivot = ary.splice(centerIndex, 1);
// 左边的小于参考值的部分
const left = [];
// 右边大于参考值的部分
const right = [];
for (let i = 0; i < ary.length; i++) {
if (ary[i] > pivot) {
right.push(ary[i]);
} else {
left.push(ary[i]);
}
}
return quickSort(left).concat(pivot, quickSort(right));
}function quickSort(ary) {
if (ary.length < 2) return ary;
// 确定参考结点的索引位置,取中间位置的结点
const centerIndex = ary.length >> 1;
// 参考结点
const pivot = ary.splice(centerIndex, 1);
// 左边的小于参考值的部分
const left = [];
// 右边大于参考值的部分
const right = [];
for (let i = 0; i < ary.length; i++) {
if (ary[i] > pivot) {
right.push(ary[i]);
} else {
left.push(ary[i]);
}
}
return quickSort(left).concat(pivot, quickSort(right));
}输入 [1, 9, 5, 3, 8, 7, 6],输出结果:[1, 3, 5, 6, 7, 8, 9 ]
上面是一种递归的实现方式,且申请了额外的空间。可以进一步优化代码,改成非递归的形式,不申请额外的内存空间。
// 对数据集合拆分
function partition(ary, start, end) {
let [i, k, j] = [start, start, end];
const pivot = ary[j];
while (k <= j) {
if (ary[k] > pivot) {
[ary[k], ary[j]] = [ary[j], ary[k]];
j--;
} else if (ary[k] < pivot) {
[ary[k], ary[i]] = [ary[i], ary[k]];
i++;
k++;
} else {
k++;
}
}
// 小于的部分 [i-1], ... 相等的部分 ... ,k 大于的部分
return [i - 1, k];
}
function quickSort(ary, start, end) {
if (start >= end) return;
const [lower, higher] = partition(ary, start, end);
quickSort(ary, start, lower);
quickSort(ary, higher, end);
}
function sortAry(nums) {
quickSort(nums, 0, nums.length - 1);
return nums;
}// 对数据集合拆分
function partition(ary, start, end) {
let [i, k, j] = [start, start, end];
const pivot = ary[j];
while (k <= j) {
if (ary[k] > pivot) {
[ary[k], ary[j]] = [ary[j], ary[k]];
j--;
} else if (ary[k] < pivot) {
[ary[k], ary[i]] = [ary[i], ary[k]];
i++;
k++;
} else {
k++;
}
}
// 小于的部分 [i-1], ... 相等的部分 ... ,k 大于的部分
return [i - 1, k];
}
function quickSort(ary, start, end) {
if (start >= end) return;
const [lower, higher] = partition(ary, start, end);
quickSort(ary, start, lower);
quickSort(ary, higher, end);
}
function sortAry(nums) {
quickSort(nums, 0, nums.length - 1);
return nums;
}上面的写法,是有名的荷兰国旗算法的实现方式。是对快速排序算法的一种变种和升华。将整个数据集合,切分为【小于部分,相等部分,大于部分】在每轮比较中,边界不断向右扩充。
其实快速排序算法,有很多的优化维度,比如参考结点的选择。如果参考结点选择合理,每轮都能命中中间数值的结点,则快速排序的性能接近最优。如果参考结点选择不合理,总是落在了边界位置,则它的时间复杂度达到最坏的情况O(n^2)。为了提高快速排序算法的性能,我们也要尽可能地让每次分区都比较平均
相比于前面介绍的(冒泡、插入、选择)排序算法,快速排序的整体时间复杂度是O(nlogn),性能要更好一些。 和选择排序一样,快速排序也会破坏原有的相对顺序,是一种不稳定的排序算法。
归并排序
归并排序,作为一种相对高效的排序,应用也比较广泛。它和上面介绍的快速排序有很多相似之处,都体现出了分治的思想。不同的是快速排序在 切分 的阶段完成了位置定位(对比和交换),而归并排序则在 合并 的阶段完成结点顺序的调整。
整体的流程分为两个阶段:拆分 和 合并,在拆分的阶段将集合不断划分成数个更小的子集,直到长度为 1 的粒度。
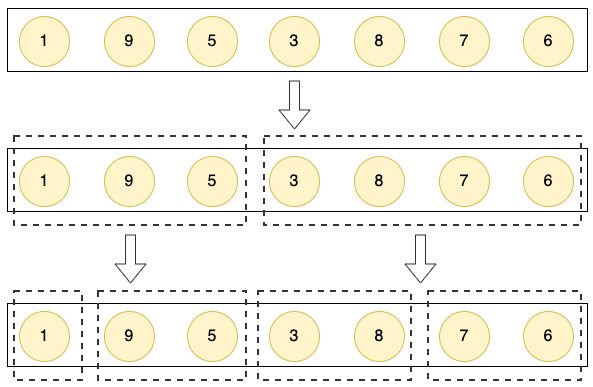
在合并的阶段,将两两相邻的子集,合并到一个新的更大的有序集合中。
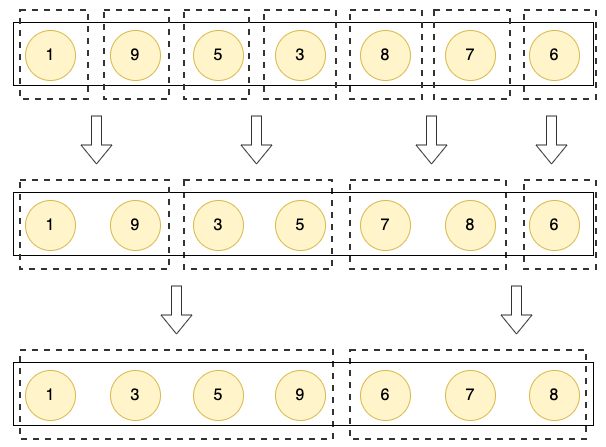
- 归并排序,充分利用了分治是思想,将大的集合拆解成小的集合,小的集合拆解成更小的集合,直到不能拆分。
- 然后再合并子集,将子集中的元素,按照顺序放到一个更大的集合中
- 最后,不断的合并,经过多轮整合就形成一个新的有序集合。
我们看一下代码实现:
// 拆分大的数据集合
function mergeSort(ary) {
if (ary.length <= 1) return ary;
const half = Math.floor(ary.length / 2);
const left = ary.slice(0, half);
const right = ary.slice(half);
// 拆分到最小粒度后,就进行合并,调用 doMerge 方法
return doMerge(mergeSort(left), mergeSort(right));
}
// 合并小的集合
function doMerge(left, right) {
const ret = [];
const [m, n] = [left.length, right.length];
let i = 0;
let j = 0;
// 将两个小集合中的元素,按大小顺序放到一个大集合中
while (i < m && j < n) {
ret.push(left[i] <= right[j] ? left[i++] : right[j++]);
}
while (i < m) {
ret.push(left[i++]);
}
while (j < n) {
ret.push(right[j++]);
}
return ret;
}// 拆分大的数据集合
function mergeSort(ary) {
if (ary.length <= 1) return ary;
const half = Math.floor(ary.length / 2);
const left = ary.slice(0, half);
const right = ary.slice(half);
// 拆分到最小粒度后,就进行合并,调用 doMerge 方法
return doMerge(mergeSort(left), mergeSort(right));
}
// 合并小的集合
function doMerge(left, right) {
const ret = [];
const [m, n] = [left.length, right.length];
let i = 0;
let j = 0;
// 将两个小集合中的元素,按大小顺序放到一个大集合中
while (i < m && j < n) {
ret.push(left[i] <= right[j] ? left[i++] : right[j++]);
}
while (i < m) {
ret.push(left[i++]);
}
while (j < n) {
ret.push(right[j++]);
}
return ret;
}输入参数:[1, 9, 5, 3, 8, 7, 6],返回新的有序集合:[1, 3, 5, 6, 7, 8, 9 ]
从上面的代码实现中,我们可以看到归并排序在合并的过程中,申请了一个新的集合,因此额外占用了存储空间,它的空间复杂度为O(n)。和快排一样它的时间复杂度为O(nlogn),同时它也是一种稳定的排序算法。
下面介绍三种应用在特定场景的排序算法,严格意义上它们不算作通用的排序算法,有其特定的应用领域。
桶排序
桶排序,顾名思义,就是将要排序的一组数据放在不同的“桶子”中。这些“桶”相当于是将数据进行了分组,将每个“桶”中的数据进行排好序,那么所有的数据,就组成了有序集合。
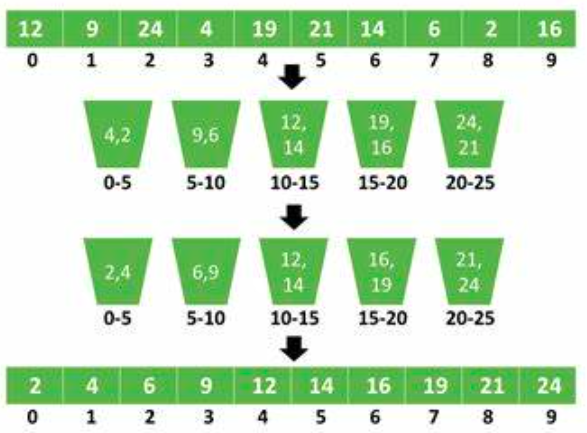
我们看一下桶排序的代码实现:
function bucketSort(arr,n) {
if (n <= 0) return;
// 1. 生成 n 个 桶
let buckets = new Array(n);
for (let i = 0; i < n; i++) {
buckets[i] = [];
}
// 2. 将集合中的元素 放置到不同的 桶 中
for (let i = 0; i < n; i++) {
let idx = arr[i] * n;
let flr = Math.floor(idx);
buckets[flr].push(arr[i]);
}
// 3. 给每个桶中的数据集合 进行排序
for (let i = 0; i < n; i++) {
buckets[i].sort(function(a,b){return a-b;});
}
// 4. 将所有桶的数据组合在一起
let index = 0;
for (let i = 0; i < n; i++) {
for (let j = 0; j < buckets[i].length; j++) {
arr[index++] = buckets[i][j];
}
}
}
// bucketSort(arr, n);function bucketSort(arr,n) {
if (n <= 0) return;
// 1. 生成 n 个 桶
let buckets = new Array(n);
for (let i = 0; i < n; i++) {
buckets[i] = [];
}
// 2. 将集合中的元素 放置到不同的 桶 中
for (let i = 0; i < n; i++) {
let idx = arr[i] * n;
let flr = Math.floor(idx);
buckets[flr].push(arr[i]);
}
// 3. 给每个桶中的数据集合 进行排序
for (let i = 0; i < n; i++) {
buckets[i].sort(function(a,b){return a-b;});
}
// 4. 将所有桶的数据组合在一起
let index = 0;
for (let i = 0; i < n; i++) {
for (let j = 0; j < buckets[i].length; j++) {
arr[index++] = buckets[i][j];
}
}
}
// bucketSort(arr, n);桶排序的时间复杂度是多少?
如果要排序的数据有 n 个,把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
桶排序的时间复杂度为O(n),为什么会有这么好的性能?原因在于,桶排序对数据的要求条件比较高:
- 要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样桶内的数据排序完之后,桶与桶之间的数据不需要再进行排序。
- 数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了
桶排序,适合外部排序的场景,比如磁盘中数据不能一次性地加载进内存中,可以划分成不同的有序区块,逐个区块进行处理。
计数排序
有这样的场景,一组数据它们的范围大致固定(0 ~ k 之间),且一般有很多重复的数值。这时候用计数排序,就比较合适了。
计数排序的过程:先确定数据的大致范围,然后设定一个位置的计数数组,根据位置的计数值和元素值,确定输出数组。举个例子,假定输入的数组为:【2,5,3,0,2,3,0,3】
- 那么可知,输入数组 inputAry 的范围是【0,5】之间。我们创建一个长度为 6 的计数数组countAry。
- 输入数组中为 0 的有两项(inputAry[3]、inputAry[6]),我们令 countAry[0] = 2
- 输入数组中为 1 的没有,则 countAry[1] = countAry[0] + 0 = 2
- 输入数组中为 2 的有两项,则countAry[2] = countAry[1] + 2 = 4
- 输入数组中为 3 的有三项,则countAry[2] = countAry[1] + 3 = 7
- 依次类推,countAry[i] = countAry[i - 1] + (i 在 inputAry 中的次数)
- 最后形成计数数组为:[2, 2, 4, 7, 7, 8]
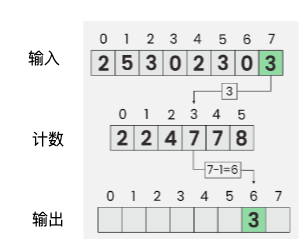
接下来,我们根据输入数组(inputAry) 和 计数数组(countAry)来确定,输出数组(outputAry)。
- 从输入数组的最后一位元素 3 开始,数字 3 对应到计数数组countAry[3] = 7,由 7 - 1 = 6确定输出位置 outputAry[6] = 3,同时计数数组的相应位置要减一(countAry[3] = 7 - 1)
- 接着 输入数组的倒数第二位元素 0,数字 0 对应到计数数组countAry[0] = 2, 由 2 - 1 = 1 确定输出位置 outputAry[1] = 0, 同时计数数组的相应位置要减一(countAry[0] = 2 - 1)
- 然后 输入数组的倒数数第三位元素 3,数字 3 对应到计数数组countAry[3] = 6, 由 6 - 1 = 5 确定输出位置 outputAry[5] = 3, 同时计数数组的相应位置要减一(countAry[3] = 6 - 5)
- 依次类推,不断重复上面的步骤,得到最终的输出结果:【0,0,2,2,3,3,3,5】
我们看一下代码实现:
function countSort(inputArray) {
let n = inputArray.length;
// 找到输入数组中最大的元素.
let maxVal = 0;
for (let i = 0; i < n; i++)
maxVal = Math.max(maxVal, inputArray[i]);
// 初始化计数数组
let countArray = new Array(maxVal + 1).fill(0);
// 计算 计数数组中的每个元素值
for (let i = 0; i < n; i++)
countArray[inputArray[i]]++;
// 计数数组进行元素值的累加
for (let i = 1; i <= maxVal; i++)
countArray[i] += countArray[i - 1];
// 根据 计数数组 生成 输出数组
let outputArray(N);
for (let i = n - 1; i >= 0; i--) {
outputArray[countArray[inputArray[i]] - 1] = inputArray[i];
countArray[inputArray[i]]--;
}
return outputArray;
}
function countSort(inputArray) {
let n = inputArray.length;
// 找到输入数组中最大的元素.
let maxVal = 0;
for (let i = 0; i < n; i++)
maxVal = Math.max(maxVal, inputArray[i]);
// 初始化计数数组
let countArray = new Array(maxVal + 1).fill(0);
// 计算 计数数组中的每个元素值
for (let i = 0; i < n; i++)
countArray[inputArray[i]]++;
// 计数数组进行元素值的累加
for (let i = 1; i <= maxVal; i++)
countArray[i] += countArray[i - 1];
// 根据 计数数组 生成 输出数组
let outputArray(N);
for (let i = n - 1; i >= 0; i--) {
outputArray[countArray[inputArray[i]] - 1] = inputArray[i];
countArray[inputArray[i]]--;
}
return outputArray;
}计数排序的设计思想很巧妙,不同于传统的比较型的排序算法,它根据数据元素的出现频次,计算出在未来输出结果集中的位置。被应用在像数据元素的集中度比较高,数据范围有限的场景。比如:考试成绩的统计(假如有几百万考生,考试成绩的范围是固定的),可以通过计数排序的方式快速得到结果。
计数排序的时间复杂度O(n+range),空间复杂度为O(range),range 是计数的范围。
基数排序
基数排序,适合数字的位数固定,但范围又不确定或是比较大,比如对10万个手机号进行排序。这就没法使用桶排序、计数排序了。
其基本思想是,将整数按位数切割成不同的数字,然后按每个位数分别比较。基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
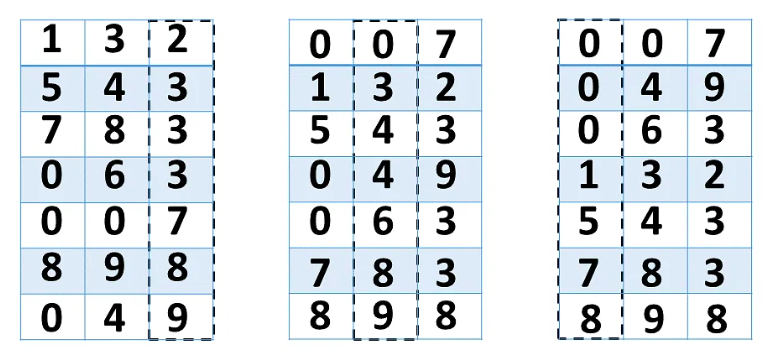
拿上图的例子来说,先从这一组数字的个位来比较排序,然后再进行十位上的数字排序,最后进行百位上的数字排序。
经过上面 3 轮的比较排序,那么这一组数字就有序了。
我们看一下代码实现:
function getMax(arr,n) {
let mx = arr[0];
for (let i = 1; i < n; i++)
if (arr[i] > mx)
mx = arr[i];
return mx;
}
// 这里又是一个计数排序
function countSort(arr,n,exp) {
let output = new Array(n); // output array
let i;
let count = new Array(10);
for(let i=0;i<10;i++)
count[i]=0;
for (i = 0; i < n; i++)
let x = Math.floor(arr[i] / exp) % 10;
count[x]++;
for (i = 1; i < 10; i++)
count[i] += count[i - 1];
// Build the output array
for (i = n - 1; i >= 0; i--) {
output[count[x] - 1] = arr[i];
count[x]--;
}
for (i = 0; i < n; i++)
arr[i] = output[i];
}
function radixSort(arr,n) {
// 找到所有数值的最大位数
let m = getMax(arr, n);
for (let exp = 1; Math.floor(m / exp) > 0; exp *= 10)
countSort(arr, n, exp);
}function getMax(arr,n) {
let mx = arr[0];
for (let i = 1; i < n; i++)
if (arr[i] > mx)
mx = arr[i];
return mx;
}
// 这里又是一个计数排序
function countSort(arr,n,exp) {
let output = new Array(n); // output array
let i;
let count = new Array(10);
for(let i=0;i<10;i++)
count[i]=0;
for (i = 0; i < n; i++)
let x = Math.floor(arr[i] / exp) % 10;
count[x]++;
for (i = 1; i < 10; i++)
count[i] += count[i - 1];
// Build the output array
for (i = n - 1; i >= 0; i--) {
output[count[x] - 1] = arr[i];
count[x]--;
}
for (i = 0; i < n; i++)
arr[i] = output[i];
}
function radixSort(arr,n) {
// 找到所有数值的最大位数
let m = getMax(arr, n);
for (let exp = 1; Math.floor(m / exp) > 0; exp *= 10)
countSort(arr, n, exp);
}基数排序的时间复杂度为O(),空间复杂度是O()
上面介绍的桶排序、计数排序、基数排序 在理想的情况下都能达到 O(n)的时间复杂度,性能比较优异,缺陷也比较明显,只适用于特定的场景。
总结
| 算法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | O(n^2) | O(1) | ✅ |
| 插入排序 | O(n^2) | O(1) | ✅ |
| 选择排序 | O(n^2) | O(1) | ❌ |
| 快速排序 | O(nlogn) | O(nlogn) | ❌ |
| 归并排序 | O(nlogn) | O(n) | ✅ |
| 桶排序 | O(n+k) | O(n+k) | ✅ |
| 计数排序 | O(n+k) | O(n+k) | ✅ |
| 基数排序 | O(n*k) | O(n+k) | ✅ |
- k为数据范围